
【LLM实战】(一)微调Qwen2.5增强text2sql能力
模型准备
由于仅作demo演示,使用7B的 Qwen2.5-7B-Instruct模型作为基座模型,进行Text2Sql指令微调。
使用ModelScope进行模型下载,速度比Huggingface快一些,建议使用conda新建一个python=3.11的环境。
创建好环境后,使用如下命令
modelscope download --model Qwen/Qwen2.5-7B --local_dir ./Qwen2.5-7B
下载完成后,模型准备部分也就完成了。
环境配置
我们微调主要使用Llama-factory库,因为他包含很好用的UI界面,并且支持多卡微调,比较方便。
具体Llama-factory的安装自行参考官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
另外,为了评估微调后的效果,我们还需要使用 evalscope库,这是阿里开发的用来评估大模型能力和性能的库,也非常好用。安装方法见官方文档:https://github.com/modelscope/evalscope/blob/main/README_zh.md
数据准备
由于我们的目的是增强大模型的text转sql的指令遵循能力,因此可以使用一些公开的数据集,比如modelscope上有一个 synthetic_text_to_sql 数据集,非常不错,包含了训练数据和测试数据,比较方便我们对比微调后的效果。
使用如下命令进行获取数据集:
modelscope download --dataset AI-ModelScope/synthetic_text_to_sql --local_dir ./sqldata
但是,这里获得的数据不能直接用于Llama-factory微调,需要手动进行一下转换,使用如下python脚本先转成jsonl格式,再转成llama-factory的json格式,这里我们只取随机1000条用来微调,减少计算时间。
import json
import random
from modelscope.msdatasets import MsDataset
def load_and_save_dataset(input_path, output_file):
"""加载原始数据集并保存为JSONL格式"""
ds = MsDataset.load(input_path)
with open(output_file, 'w', encoding='utf-8') as f:
for item in ds['train']:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"数据已成功保存至 {output_file}")
return output_file
def preprocess_data(input_file, output_file, sample_size=1000000):
"""预处理数据:合并sql_prompt和sql_context,并采样"""
def preprocess_line(line):
data = json.loads(line)
input_text = (f"请根据以下数据库模式和内容生成相应的SQL查询。只返回SQL语句,不要返回其他任何内容。\n"
f"数据库模式和内容:\n{data['sql_context']}\n"
f"问题: {data['sql_prompt']}")
return json.dumps({
"query": input_text,
"response": data["sql"]
}, ensure_ascii=False)
with open(input_file, 'r', encoding='utf-8') as infile:
lines = infile.readlines()
sampled_lines = random.sample(lines, k=min(sample_size, len(lines)))
with open(output_file, 'w', encoding='utf-8') as outfile:
for line in sampled_lines:
outfile.write(preprocess_line(line) + '\n')
return output_file
def convert_to_llamafactory(input_file, output_file, sample_size=1000):
"""转换为LLaMA-Factory兼容格式"""
def convert_line(line):
data = json.loads(line)
return {
"instruction": data["query"],
"input": "",
"output": data["response"]
}
with open(input_file, 'r', encoding='utf-8') as infile:
lines = infile.readlines()
sampled_lines = random.sample(lines, k=min(sample_size, len(lines)))
converted_data = [convert_line(line) for line in sampled_lines]
with open(output_file, 'w', encoding='utf-8') as outfile:
json.dump(converted_data, outfile, ensure_ascii=False, indent=2)
print(f"已成功生成 LLaMA-Factory 兼容的微调数据文件: {output_file}")
return output_file
# 主流程
def main():
# 第一步:加载并保存原始数据
raw_jsonl = load_and_save_dataset('./sqldata', 'sqldata_train.jsonl')
# 第二步:预处理数据
preprocessed_jsonl = preprocess_data(raw_jsonl, 'sqldata_train_preprocessed.jsonl')
# 第三步:转换为LLaMA-Factory格式
final_output = convert_to_llamafactory(preprocessed_jsonl, 'llamafactory_sql_finetune_1000.json')
if __name__ == "__main__":
main()
处理之后可以得到能够进行Llama-factory微调的数据集文件 llamafactory_sql_finetune_1000.json,我们将该文件移动到Llama-factory目录下\data\custom文件夹中,并在\data\dataset_info.json最后添加如下内容:
"sql_dataset":{
"file_name": "custom/llamafactory_sql_finetune_1000.json"
}
至此,微调数据准备完成。
另外,实际上还需要准备一份测试数据,供evalscope进行测试,这里直接复用上面代码中的preprocess_data函数,采样个数可以设置小一些比如100。
数据集大概样子如下:
[
{
"instruction": "请根据以下数据库模式和内容生成相应的SQL查询。只返回SQL语句,不要返回其他任何内容。\n数据库模式和内容:\nCREATE TABLE solar_projects (id INT, name VARCHAR(255), energy_production FLOAT);\n问题: What's the total energy production from solar projects?",
"input": "",
"output": "SELECT SUM(energy_production) FROM solar_projects;"
},
{
"instruction": "请根据以下数据库模式和内容生成相应的SQL查询。只返回SQL语句,不要返回其他任何内容。\n数据库模式和内容:\nCREATE TABLE hospitals (hospital_id INT, country VARCHAR(20), has_telemedicine BOOLEAN); INSERT INTO hospitals (hospital_id, country, has_telemedicine) VALUES (1, 'India', TRUE), (2, 'South Africa', FALSE);\n问题: Identify the number of rural hospitals with telemedicine services in India and South Africa.",
"input": "",
"output": "SELECT country, COUNT(*) FROM hospitals WHERE country IN ('India', 'South Africa') AND has_telemedicine = TRUE GROUP BY country;"
}
]
模型微调
使用 llamafactory-cli webui命令打开llama-factory的UI界面。
- 调整语言为中文
- 模型名称选择Qwen-7B
- 模型路径输入刚才的模型文件夹路径
- 微调方法选择lora,lora rank 为8
- 学习率为5e-5,epoch为3
- 数据集选择
sql_dataset,也就是刚刚放进去的数据集
开始训练。
总loss变化如下图: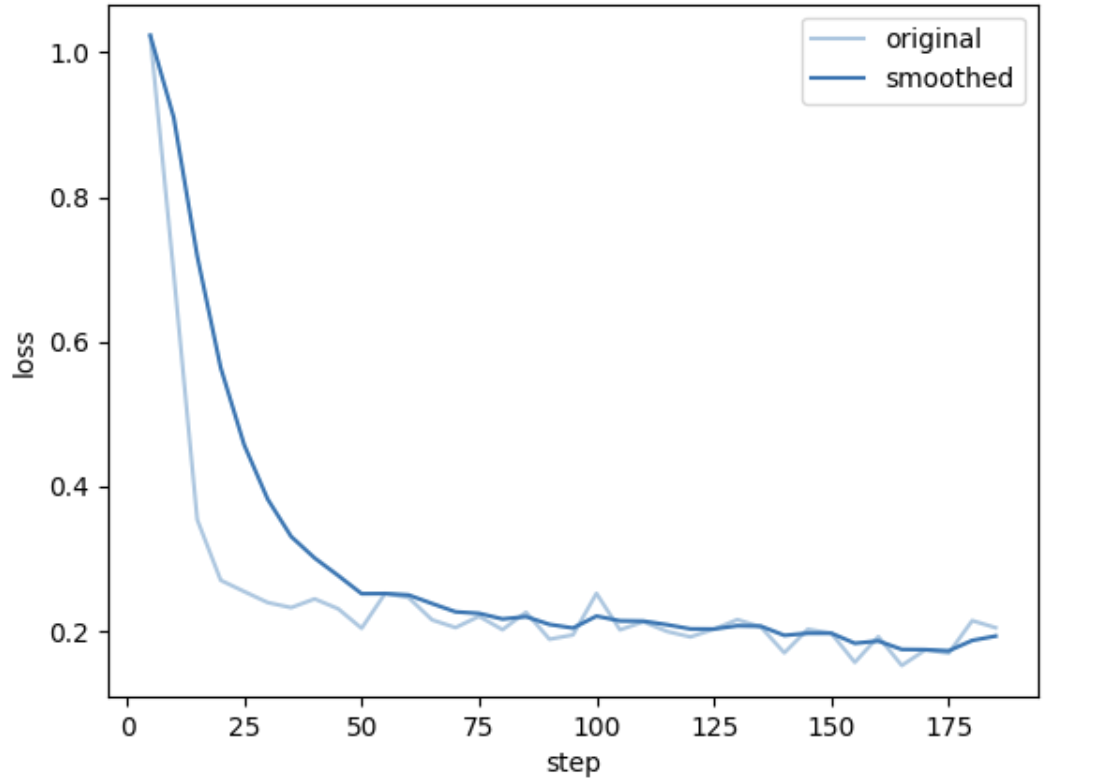
说明训练是有效果的。
权重合并
训练完Lora后,需要和原始权重进行merge,这一步操作也可以在webui中直接实现。
在webui的export栏中,设置好最大分块大小和是否有量化的一些选项,直接点击导出即可。
模型测试
微调完成后,需要对比一下模型微调前后的效果,这里就可以使用evalscope进行评估,使用我们自己构造的测试数据集。
运行如下代码:
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='./SFT-Qwen2.5-7B', # 更改为微调前和微调后的模型路径
datasets=['general_qa'], # 使用自定义数据集类型
dataset_args={
'general_qa': {
"local_path": ".",
"subset_list": ["sqldata_test_100_preprocessed"], # 对应 sqldata_train.jsonl 文件
"input_key": "input", # 模型输入字段
"output_key": "prediction", # 模型输出保存字段
"label_key": "label" # 实际标签字段(用于评估)
}
},
)
run_task(task_cfg=task_cfg)
结果对比如下:
微调前:
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|---|---|---|---|---|---|---|
| Qwen2.5-7B | general_qa | Rouge-1-R | sqldata_test_100_preprocessed | 100 | 0.7642 | default |
| Qwen2.5-7B | general_qa | Rouge-1-P | sqldata_test_100_preprocessed | 100 | 0.6457 | default |
| Qwen2.5-7B | general_qa | Rouge-1-F | sqldata_test_100_preprocessed | 100 | 0.6915 | default |
| Qwen2.5-7B | general_qa | Rouge-2-R | sqldata_test_100_preprocessed | 100 | 0.5884 | default |
| Qwen2.5-7B | general_qa | Rouge-2-P | sqldata_test_100_preprocessed | 100 | 0.4899 | default |
| Qwen2.5-7B | general_qa | Rouge-2-F | sqldata_test_100_preprocessed | 100 | 0.527 | default |
| Qwen2.5-7B | general_qa | Rouge-L-R | sqldata_test_100_preprocessed | 100 | 0.7402 | default |
| Qwen2.5-7B | general_qa | Rouge-L-P | sqldata_test_100_preprocessed | 100 | 0.6358 | default |
| Qwen2.5-7B | general_qa | Rouge-L-F | sqldata_test_100_preprocessed | 100 | 0.6736 | default |
| Qwen2.5-7B | general_qa | bleu-1 | sqldata_test_100_preprocessed | 100 | 0.6238 | default |
| Qwen2.5-7B | general_qa | bleu-2 | sqldata_test_100_preprocessed | 100 | 0.5028 | default |
| Qwen2.5-7B | general_qa | bleu-3 | sqldata_test_100_preprocessed | 100 | 0.4184 | default |
| Qwen2.5-7B | general_qa | bleu-4 | sqldata_test_100_preprocessed | 100 | 0.3461 | default |
微调后:
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|---|---|---|---|---|---|---|
| SFT-Qwen2.5-7B | general_qa | Rouge-1-R | sqldata_test_100_preprocessed | 100 | 0.7664 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-1-P | sqldata_test_100_preprocessed | 100 | 0.816 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-1-F | sqldata_test_100_preprocessed | 100 | 0.7831 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-2-R | sqldata_test_100_preprocessed | 100 | 0.6204 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-2-P | sqldata_test_100_preprocessed | 100 | 0.6652 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-2-F | sqldata_test_100_preprocessed | 100 | 0.6352 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-L-R | sqldata_test_100_preprocessed | 100 | 0.7429 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-L-P | sqldata_test_100_preprocessed | 100 | 0.8014 | default |
| SFT-Qwen2.5-7B | general_qa | Rouge-L-F | sqldata_test_100_preprocessed | 100 | 0.7622 | default |
| SFT-Qwen2.5-7B | general_qa | bleu-1 | sqldata_test_100_preprocessed | 100 | 0.7737 | default |
| SFT-Qwen2.5-7B | general_qa | bleu-2 | sqldata_test_100_preprocessed | 100 | 0.6583 | default |
| SFT-Qwen2.5-7B | general_qa | bleu-3 | sqldata_test_100_preprocessed | 100 | 0.5919 | default |
| SFT-Qwen2.5-7B | general_qa | bleu-4 | sqldata_test_100_preprocessed | 100 | 0.5369 | default |
可以看到,我们只是简单微调了一下,但是在多项指标上都有明显进步,尽管模型在其他方面的能力,比如写作、角色扮演等方面能力有所下降,但是主要的text2sql的能力有明显提升,这就是微调的作用。
后话
实际上,之前有段实习的经历就是做大模型text2sql的项目,根据之前的项目经验,这个小demo还有以下改进方向:
- 增大微调数据集量,精细选一下微调参数,采用更大的模型进行微调
- 因为实际落地的时候肯定使用中文进行对话,但是微调数据集是英文的,因此可以在数据处理阶段使用大模型将问句转换为中文,而不改变里面的schema描述和查询主体。
- 引入领域知识一起微调,比如想做医疗领域的垂直项目数据库的查询,可以考虑引入一些医疗问答对话知识,增强领域表达能力。
- 约束模型输出结果,使用DPO方法进行偏好选择后训练,防止出现生成的sql语句格式不对、大小写错误等问题。
微调Qwen2.5增强text2sql能力&pics=/upload/training_loss-aROd.png&summary=){kind=link}
微调Qwen2.5增强text2sql能力&pics=/upload/training_loss-aROd.png&desc=){kind=link}