
基于N-gram和LSTM的科技文本生成系统
爬虫过程
数据来源:
腾讯新闻-科技板块
网易新闻-科技板块
新浪新闻-科技板块
一开始,在爬取腾讯新闻科技板块的新闻时,本来以为使用python的request库和BeautifulSoup库直接解析html内容就可以轻松得到新闻具体的URL,但是在实践操作的时候发现爬不到任何数据,排查一下原因发现是腾讯新闻的列表是动态加载的,导致直接使用get方法是无法得到想要的数据的。
那怎么对这种动态数据的进行爬取呢?
主要有两种方法:
使用selenium库的webdriver来模拟浏览器操作,进而获取数据,这种方法最直观且容易理解。
使用浏览器控制台,手动找到动态加载的网络进程,将参数copy下来进行分析,然后在代码中附上参数进行post访问,就可以获得正确的数据。
这两种方法我都进行了尝试,在使用第一种方法的时侯,因为webdriver需要自己配置浏览器内核文件,可惜的是,官网提供的chrome内核网址链接失效了,所以最终没有选择该方法进行爬取数据。
所以我只能选择使用第二种方法了,下面以腾讯、网易、新浪三个新闻网站为例,介绍我具体的爬取过程。
腾讯新闻
在腾讯新闻科技板块页面中,通过查看网页的控制台中请求的网络进程,可以看到,getPCList即为获取新闻列表的网络请求,如下图所示:
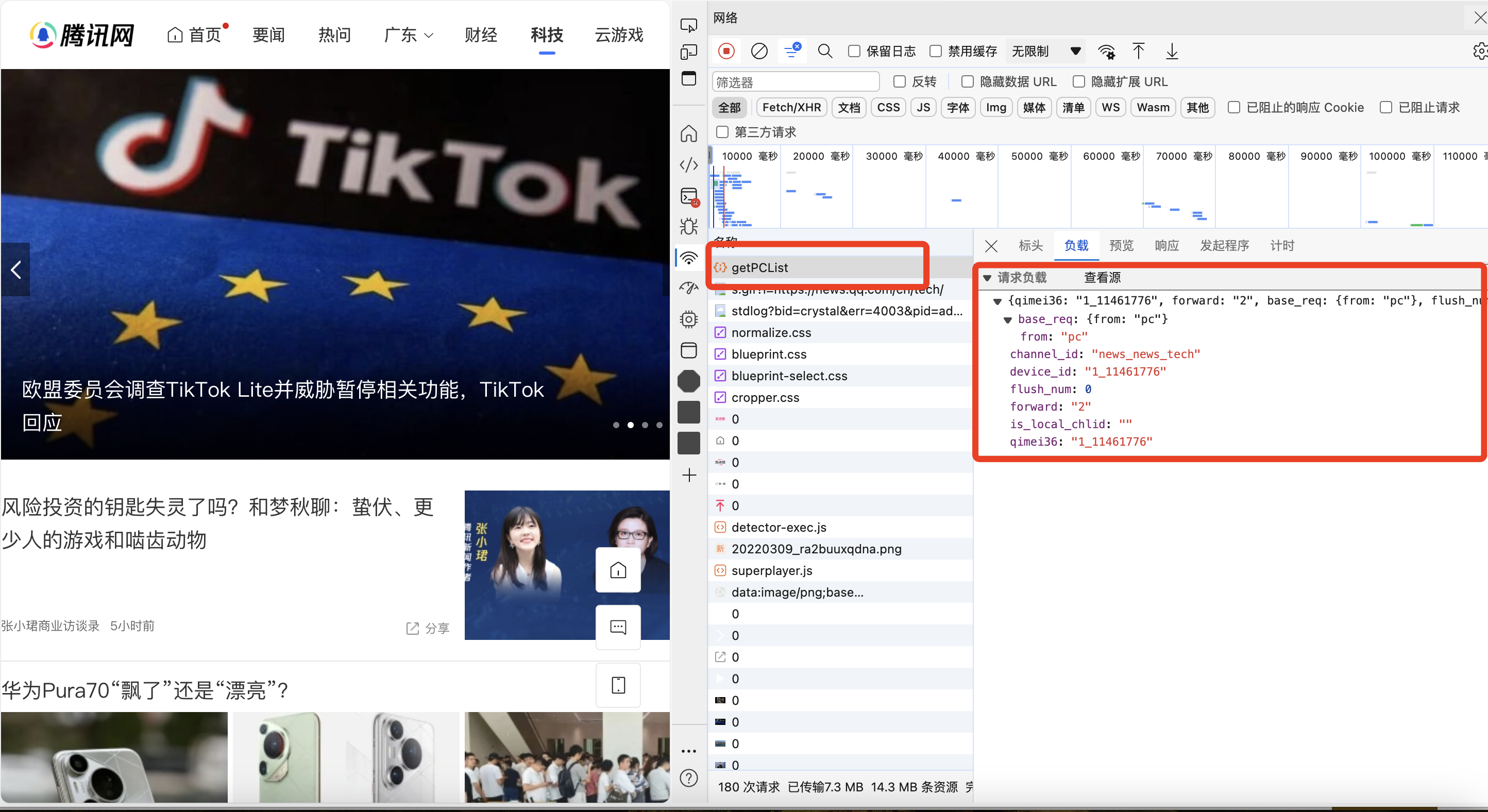
右边为附加的请求参数,具体为:
parm = {
"qimei36": "0_ddebbe7570e02",
"forward": "2",
"base_req": {
"from": "pc"
},
"flush_num": 0,
"channel_id": "news_news_tech",
"device_id": "0_ddebbe7570e02",
"is_local_chlid": ""
}将这些参数在代码中加入post请求中,即可获取正确的新闻列表,通过多次获取更多新闻,发现一些参数变化规律:
forward参数第一次请求为2,后续进行更多请求时参数均为1
flush_num参数会一直递增
只要在代码中将该规律应用到多次请求中,就可以保证每次获得的新闻是不同的。
另外,腾讯新闻对爬虫的检查比较严格,尽管我把每次请求时间访问间隔设置到10秒到20秒的随机数,但是请求多了依然会被ban掉。
还有要注意的是,在爬取数据的时候需要注意每条新闻的类型,有些是纯video类型的,针对这种情况,可以对标签多做一次筛选,以免后续爬取具体内容时因为格式不同而报错。
最终在腾讯新闻上爬取了1202条文本新闻。
网易新闻
网易新闻的爬取是三个网站中最容易的,只需要用get方法访问特定的页面api即可,但是他的新闻可爬取数量是最少的,因为他限制了用户只能访问最多最近的400条新闻。
具体页面的api图如下所示:
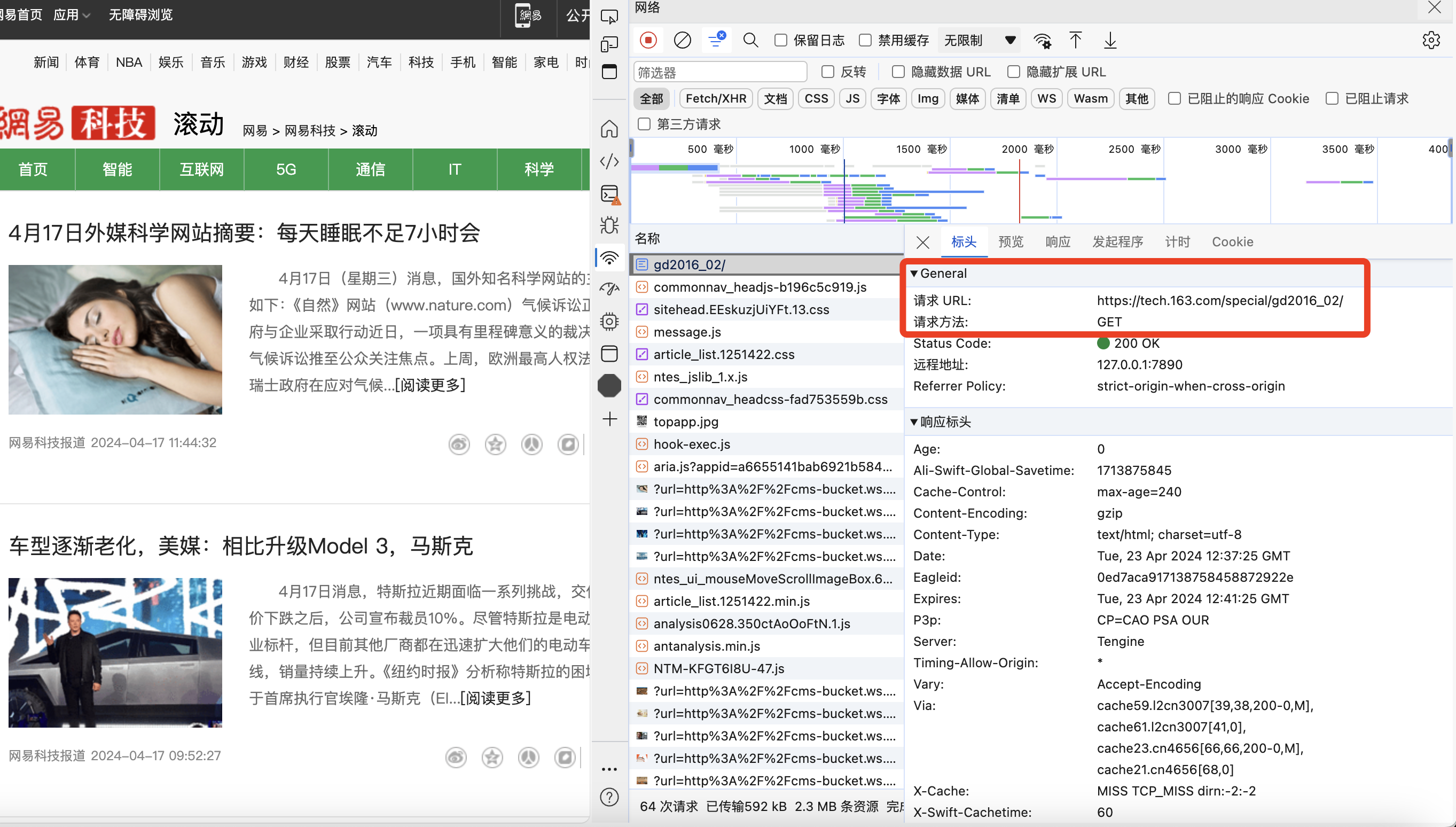
经过不断切换页面尝试可以发现其规律:
url最后两位数字即为新闻列表的页面数
首页的url最后两位无单独数字
按此规律写代码进行依次爬取,即可获得所有能访问的新闻链接。
由于网易新闻科技板块自身限制,故在网易新闻中共爬取433条新闻数据。
新浪新闻
新浪新闻的爬取过程稍微麻烦一些,总体上也是通过分析浏览器网络请求的规律,具体为发现不断下拉页面请求时,会有很多tianyi开头的网络请求,如下图所示:
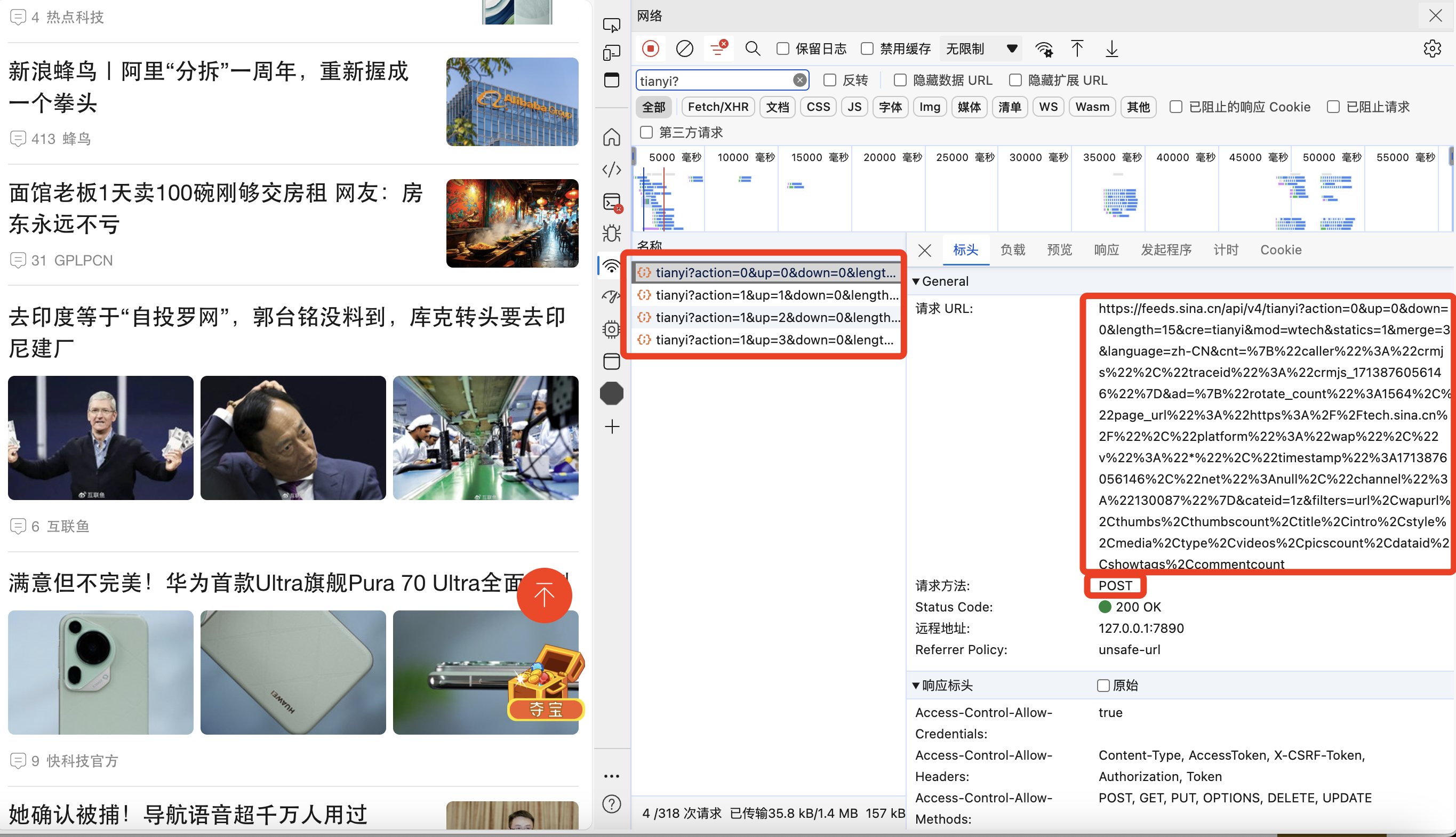
具体规律如下:
action参数第一次请求为0,后续进行更多请求时参数均为1
up参数会一直递增
可以看出来,action参数和up参数与腾讯新闻的规律类似,这样可以通过更改url中对应位置的参数,进行post请求,即可获得新闻列表的信息。
最终在新浪新闻中爬取2290条新闻数据。
爬取内容
在获得所有的新闻url后,还需要对这些url使用get访问方法获得具体的新闻内容,这里只需要使用BeautifulSoup进行解析,然后根据不同网站的内容模板进行查找即可。
这里有意思的是,新浪的新闻内容在爬取的过程中竟然发现三种不同的模板,有的一条链接里还出现两个不同的新闻,对应两套模板......但是好在处理起来也不复杂,多设立几个IF判断就能处理了。
总结下来,共爬取腾讯新闻1202条,网易新闻433条,新浪新闻2290条,总计3725条,均为科技板块的新闻内容。
预处理过程
在爬取完新闻数据后,还需要对数据进行预处理,转换为计算机能处理的格式,才能进行后续的训练和预测,在此过程中,我主要考虑了四个方面,分别是:
文字格式处理
分句处理
分词处理
停用词处理
首先,在爬取大量数据后,因为不同来源的新闻可能在文本格式上差别比较大, 比如各种符号的使用以及换行符的处理,为了后续的分句和分词过程能够统一进行,首先需要对文字格式做一些处理,我采用的具体方式为:
首先对每条新闻的\r\n和\n换行回车字符替换为全角感叹号
再将所有的小写字母转换为大写字母
然后将所有的繁体字都转换为简体字
最后将新闻文本中的半角字符全部转换为全角字符
在做完这些处理之后,做分句就比较简单了,对每个新闻按照句号、感叹号、问号、分号等进行分句即可。
在分词过程中,我尝试了两种现有的分词中文库,jieba分词和pkuseg分词,综合对比两类方法的最终结果的优劣,选择使用jieba分词方法。
在每一句分词完成后,还需要对停用词进行过滤,以免让一些无意义的词占据过高的词频。我选用的停用词表为以下的并集:cn_stopwords.txt、hit_stopwords.txt、stopwords/baidu_stopwords.txt、scu_stopwords.txt。
在数据预处理过程中,还完成了词表的构建,每个词都对应一个序号,保存到vocab.txt文件中。
总结,在预处理完成之后,可以得到包含所有新闻内容的分句分词结果和一个词表文件。
模型构建和训练
模型构建部分主要分为两块,分别是ngram模型的构建和LSTM模型的构建,下面将分别对其进行介绍。
ngram模型
对于ngram模型,其基本原理公式为:
n等于2时,
这是假设句子中每个单词出现的概率都和它前一个单词出现的概率有关。
在数据预处理完成后我们已经完成了对语料库的构建,只需要根据语料库中各个单词的计数,利用最大似然估计来估计该单词出现的概率。
其中,C(w_{i-1},w_i)表示w_{i-1}和w_i前后相邻一起出现的次数。
此外,有些单词处在句子的开头和末尾,需要进行特殊处理,我在代码中采用的是<s>表示句子的开始,使用</s>表示句子的结束。
将各个单词的成对出现频率统计完成后,就完成了bigram模型(n=2)的构建,后面进行推断的时候只需要再模型语料库中查找对应最大概率的词作为预测结果即可。类似的过程也可以完成n=3的trigram的构建。
LSTM模型
主要可以分为以下三个部分:数据编码、模型定义、训练过程
数据编码
使用数字索引映射,建立双向映射表,方便后续训练和预测(也用了Word2Vec,但是效果很差)
自定义WordDataset类创建了一个自定义的数据集,其中每个样本包含了输入序列和目标序列
模型定义
主要介绍一些LSTM的关键参数:
嵌入维度(embedding_dim):100。
隐藏单元数量(hidden_dim):每个 LSTM 单元的隐藏单元数量为128。
层数(num_layers):LSTM的层数为2。
模型结构:包含了一个嵌入层、一个 LSTM 层和一个全连接层
训练过程
选择使用Adam优化器,并使用交叉熵损失作为损失函数(也尝试了MSE,效果不如交叉熵损失),在训练过程中进行前向传播、计算损失、反向传播和参数更新等。
在200个epoch的训练过程中,每个epoch结束后,都对模型使用测试集进行一次评估,并且记录loss变化,结果如下:
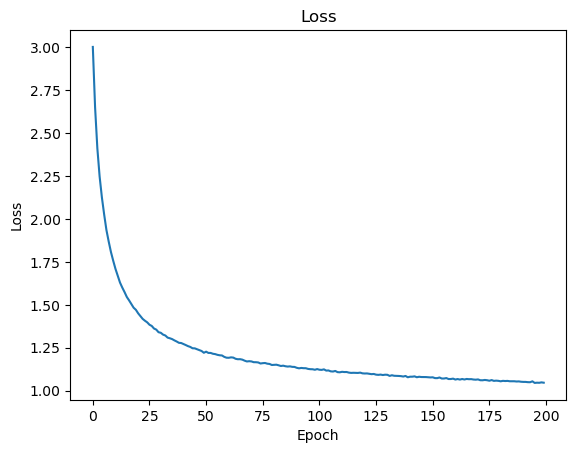
可以看到,随着训练的不断进行,loss是一直呈下降趋势的,从3.0损失降低到接近1.0,说明代码的训练过程基本上是没有问题的。
下面是准确率的变化图:
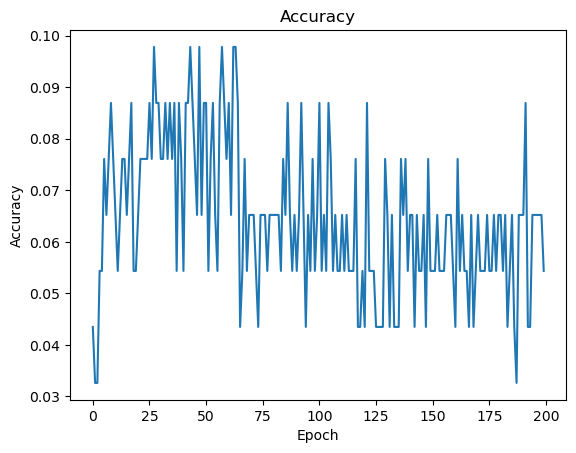
从趋势上看,基本上是先上升后下降的过程,这也符合从欠拟合到过拟合的流程,但是就是最高准确率也才0.1,个人感觉更多是训练数据的问题。
预测指标和结果
这部分主要分为两块,分别是对ngram结果的分析和对LSTM的结果分析。
ngram模型
在构建完成ngram模型后,使用测试集进行评估,在具体对比结果之前,还需要对测试集中的句子进行相同的预处理过程,具体流程为:
对每个句子,首先使用split方法将[MASK]前的句子切分出来
再对前面的句子做分词和停止词的处理
取出mask前的最后n-1个单词
使用ngram模型进行预测下一个单词
将预测的单词和最终结果进行对比,计算准确率
其实在一开始爬取新闻数量规格如下:
腾讯新闻:673条 网易新闻:400条 新浪新闻:576条
共计1649条新闻的数据量情况下,top1的准确率只有0.06,检查代码发现并没有什么问题,检查测试集后发现里面很多跟科技板块不相关的条目,于是怀疑是数据量不够,所以后续又加大了爬取力度,腾讯新闻共1202条,网易新闻共433条,新浪新闻共2290条,总计3725条数据,均按作业要求爬取来自科技板块。
在加大数据量后,bigram模型的准确率达到0.10,比之前好一些了。
此外,我还调整了topk的取值,当k取不同值时,评估Ground Truth在回答中的比例,如图所示:
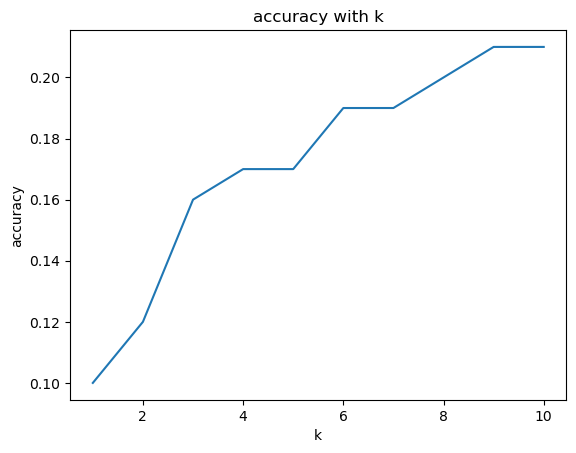
可以看到,随着k的不断增大,其实正确答案也在候选答案中有所出现,top10的准确率上升到0.21。
但是受限于预料领域没有完全匹配,所以总体准确率上不太乐观。
为什么说是受限于训练数据呢,因为我同时也构建了trigram模型,采用同样的数据集,但是所有的预测结果均为空,即准确率为0,说明测试集中的数据对很多根本就没在训练集中出现过,所以感觉主要还是数据集覆盖不全面导致的。
部分结果展示:
问1:……本轮疫情发生以来,广东各地区各部门结合自身实际,细化[MASK]执行方案 答1:['行业'] 正确答案:防控
问2:优衣库在[MASK]的开店重点将从门店数量转向单店盈利能力。 答2:['中国'] 正确答案:中国
问3:一年前文心[MASK]发布的时候,我们内部是有过非常激烈的讨论的 答3:['模型'] 正确答案:刚刚
问4:而这些网络正能量作品的涌现,正是对正[MASK]精神的积极回应和有力践行。 答4:['处于'] 正确答案:能量
问5:2024财年上半年,优衣库在中国大陆市场的收益增长,溢利小幅下降,毛利率[MASK]。 答5:['提升'] 正确答案:下滑
从示例结果也可以看出来,有些词虽然没有回答正确,但是其实只结合左右邻居词汇的话,并不突兀,例如问1中的答案,对于词频较小的词,几乎很难预测正确,例如问3中的回答,其实"模型"放在这里看起来也是完全没有问题的。 另外,ngram对词性是有一定的把握的,例如问5中,提升和下滑为同一词性,但是ngram缺少对上下文的结合,导致回答错误。
LSTM模型
在具体对比结果之前,需要对数据做与ngram模型一节中相同的预处理过程。
最终训练得到的LSTM模型中准确率最高的为0.10,与bigram模型的准确率相同。
同样我也对topk值进行了调整,当k取不同值时,评估Ground Truth是否在候选回答中,准确率变化如图所示:
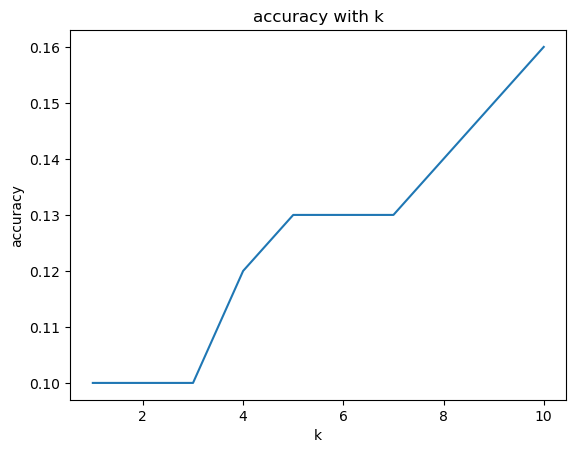
基本上也是随着k值增加,准确率也是上升的。
问1:……本轮疫情发生以来,广东各地区各部门结合自身实际,细化[MASK]执行方案 答1:['中'] 正确答案:防控
问2:优衣库在[MASK]的开店重点将从门店数量转向单店盈利能力。 答2:['中国'] 正确答案:中国
问3:一年前文心[MASK]发布的时候,我们内部是有过非常激烈的讨论的 答3:['模型'] 正确答案:刚刚
问4:而这些网络正能量作品的涌现,正是对正[MASK]精神的积极回应和有力践行。 答4:['能量'] 正确答案:能量
问5:2024财年上半年,优衣库在中国大陆市场的收益增长,溢利小幅下降,毛利率[MASK]。 答5:['下滑'] 正确答案:下滑
从示例结果来看,与ngram对比,在问1中回答的似乎牛头不对马嘴,但这也说明了LSTM不是仅仅考虑词频,而是结合了更多因素。 在问2和问3中,表现都和ngram模型一致,说明对于重点词频的单词,LSTM是能够较为准确进行把握的。 在问4和问5中,LSTM的优势就表现出来了,即对上下文的结合能力,问4中前文有"正能量"词汇,LSTM能捕捉到此信息并返回准确结果,问5中前一句为下降,所以毛利率应该为"下滑"而不是ngram模型给出的"提升"。
对比总结
对比LSTM和ngram在部分示例上的表现,可以看出LSTM对上下文信息的结合还是有作用的,ngram受限于词频的统计,难以结合语境给出准确答案,LSTM在这方面的表现要强于ngram。
另外,我还更改了输出的轮次限制,让两个模型分别以"中国"开始输出长度为20的句子,ngram模型很快就会陷入不动点收敛,在两个词之间反复横跳,例如:
['中国','市场','规模','达','10','月','日','消息','称','公司','内部','人士','透露','公司','内部','人士','透露','公司','内部','人士']
LSTM在这方面就表现好很多,如下:
['中国','传媒','零售','行业','发展','现状','重视','程度','发展','阶段','程度','改善','机器人','市场','规模','效应','生产','效率','产品质量','竞争力']
可以看到,LSTM的输出虽然也重复出现了"程度",但是由于上下文不同,会很快跳出重复点,整体的流畅度比ngram要好很多。虽然他们在测试集上的准确率相同,但是其实感觉还是LSTM的能力要强一些。
总结
作为NLP课程的中期大作业,主要是熟悉一些数据处理和操作流程以及Pytorch的操作,效果倒是次要的(并且测试集根本几乎完全不相关)。
{kind=link}
{kind=link}