
基于Transformer的中英文本翻译
大致流程:
- 数据获取
- 数据预处理
- 构建词表和映射
- Encoder构建
- Decoder构建
- 训练相关参数
- 模型评估
数据获取
选用的是指定的WMT18(News Commentary)数据集,其实这个数据集在多个网站都有公开资源(Github、Huggingface,还有国内各种博客网站),但是有些网站的数据集是错误很多的(比如下载下来发现中英文行号对不齐,数据量不够等等问题),折腾一番后找到官方地址下载Translation Task - EMNLP 2018 Third Conference on Machine Translation (statmt.org)
下载后有两个文件,分别命名为dataset.en和dataset.zh,表示英文和中文的数据集,如下图所示,每一行为一个句子,两边互相对应:

数据预处理
虽然我们从官方网站下载到了"最正版"的数据,但是因为这个数据已经很久没有人维护了,里面依然存在一些符号混乱的情况,为了方便后续模型的训练,还需要做一些数据清洗。
具体来说,对于中文语料,我采用的方法是使用正则表达式来依次执行下面的过程:
- 删除其中的HTML实体占用符号
- 删除其中的特殊符号
- 删除其中的连续空白字符
- 使用Spacy进行分词和去除标点符号。
对于英文预料,因为本身比较规整,我仅简单使用Spacy进行分词。
具体代码实现如下:
def tokenize_en(text):
return [token.text.lower() for token in spacy_en.tokenizer(text) if token.text not in string.punctuation]
def tokenize_zh(text):
text = re.sub(r"&#[0-9]+;", r"", text)
text = re.sub(r"�", r"", text)
for zh, en in [("。", "."), ("!", "!"), ("?", "?"), (",", ",")]:
text = text.replace(zh, en)
text = re.sub(u"[^a-zA-Z0-9\u4e00-\u9fa5,.!?]", u" ", text)
text = re.sub(r"\s+", r" ", text)
return [token.text for token in spacy_zh(text) if token.text not in string.punctuation]
构建词表和映射
遵循作业要求和方便后续模型处理,我定义了三个标记词:
BOS:表示句子的开头,索引为 0EOS:表示句子的结尾,索引为 1PAD:表示batch的填充词,索引为 2
定义一个词表类Vocab,用来存放中文和英文的词表以及索引对应关系,代码如下:
BOS_token = 0
EOS_token = 1
PAD_token = 2
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "BOS", 1: "EOS", 2: "PAD"}
self.n_words = 3
def addSentence(self, sentence):
for word in sentence:
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
Encoder构建
首先,我使用的是Pytroch的库来构建整个网络架构。
**核心逻辑:**将输入序列通过嵌入层转换为向量,然后通过双向LSTM处理,最后合并两个方向的状态,为后续的解码器提供信息
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size // 2, batch_first=True, bidirectional=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.lstm(embedded)
hidden = self._cat_directions(hidden)
cell = self._cat_directions(cell)
return output, (hidden, cell)
def _cat_directions(self, h):
if self.lstm.bidirectional:
h = torch.cat([h[0:h.size(0):2], h[1:h.size(0):2]], dim=2)
return h
Decoder构建
**核心逻辑:**使用Bahdanau注意力机制,在每个时间步骤中都会考虑编码器的全部输出,并通过计算注意力权重来决定在生成当前输出时应该“注意”编码器输出的哪些部分。另外,在训练的时候采用了Teacher forcing策略,代码有具体注释解释。
class AttnDecoder(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1):
super(AttnDecoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.attention = BahdanauAttention(hidden_size)
self.lstm = nn.LSTM(hidden_size + hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout_p)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(BOS_token)
decoder_hidden = (encoder_hidden[0], encoder_hidden[1]) # 使用encoder的隐藏状态和细胞状态初始化decoder
decoder_outputs = []
attentions = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden, attn_weights = self.forward_step(
decoder_input, decoder_hidden, encoder_outputs
)
decoder_outputs.append(decoder_output)
attentions.append(attn_weights)
if target_tensor is not None:
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach()
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
attentions = torch.cat(attentions, dim=1)
return decoder_outputs, decoder_hidden, attentions
def forward_step(self, input, hidden, encoder_outputs):
embedded = self.dropout(self.embedding(input))
query = hidden[0].permute(1, 0, 2) # LSTM的hidden是一个元组(h, c),这里只用h
context, attn_weights = self.attention(query, encoder_outputs)
input_lstm = torch.cat((embedded, context), dim=2)
output, hidden = self.lstm(input_lstm, hidden)
output = self.out(output)
return output, hidden, attn_weights
训练相关参数
训练数据条数:80k,(本来用6k训看看效果的,惨不忍睹,所以加大了一点点)
损失函数:交叉熵损失
中文词表长度:53379
英文词表长度:36165
Batch_size:32
Hidden_size:128
Epoch:140,(不停的训了26个小时)
Encoder和Decoder的具体Tensor维度如下所示:
Encoder(
(embedding): Embedding(53379, 128)
(lstm): LSTM(128, 64, batch_first=True, bidirectional=True)
(dropout): Dropout(p=0.1, inplace=False)
)
AttnDecoder(
(embedding): Embedding(36165, 128)
(attention): BahdanauAttention(
(Wa): Linear(in_features=128, out_features=128, bias=True)
(Ua): Linear(in_features=128, out_features=128, bias=True)
(Va): Linear(in_features=128, out_features=1, bias=True)
)
(lstm): LSTM(256, 128, batch_first=True)
(out): Linear(in_features=128, out_features=36165, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
模型评估
Loss变化
训练过程中的loss变化如下:
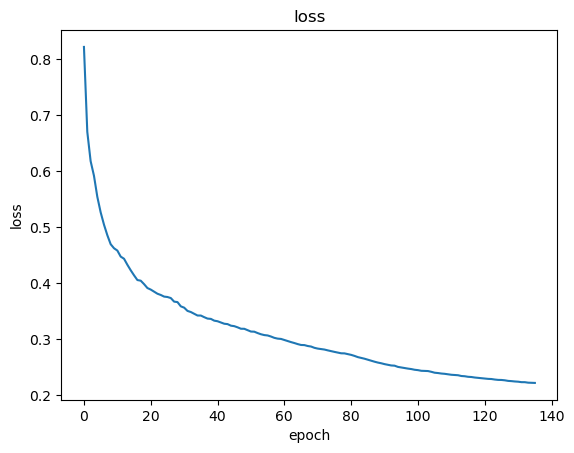
基本上是在一直下降的,直到后面变化非常缓慢,由于训练的时候忘了加验证集的loss记录,所以验证集的loss变化没有办法展示,但是在训练的时候我保存了每次epoch的模型权重,所以直接重新加载然后跑一次验证集的评估就好了,结果如下:
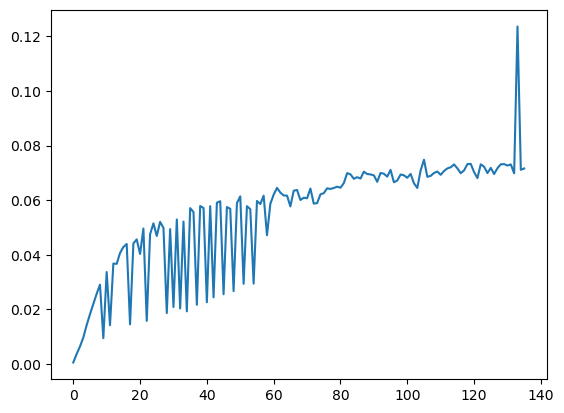
可以看出,大致是增长趋势的,说明当前的训练轮次还是没有达到过拟合的状态的(因为验证集与训练集没有交集),但是由于设备资源限制,我也只训练到这里了。
选择最后一次训练的模型,在测试集中进行测试,得到的结果使用BLEU-4进行评估,分布如下:
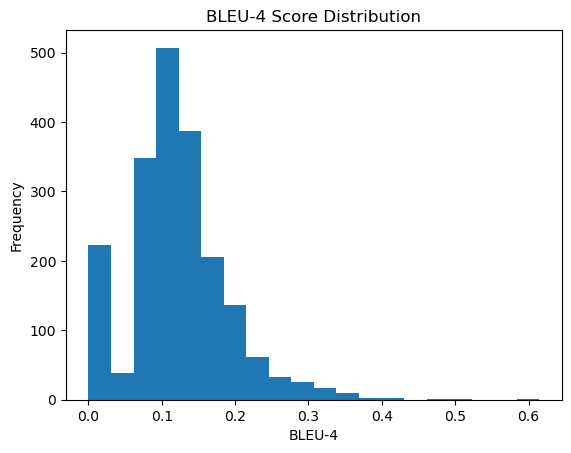
可以看到,其实还有有很多低分的,不过剩余的整体部分还是大致服从高斯分布的,说明测试样本中有一部分样本与训练样本相似度太低,导致模型没有很好的泛化,感觉还是训练数据不够广泛的问题,因为我选择数据是直接按数据集的固定位置选的,并非随机采样。
结果分析
在测试集中测试,测试集共2000条数据,与训练样本无任何交集。
我的代码里也写了Beam Search策略,放在utils.py,函数名是beam_search(),用的时候需要把评估部分的evaluate()换成beam_search(),但是实际用下来发现对翻译结果几乎没有提升,说明训练其实是充分的,模型大部分情况下都能找到概率值最大的路径。
我选了几条比较有代表性的样例进行分析,由于普遍的Bleu得分不是很高,所以选择的是能反映出模型特性和改进点的一些样例
origin: ['但是', '鉴于', '局势', '没有', '什么', '其他', '更', '好的', '办法']
reference: yet in light of the situation there is no better alternative
candidate: but there is no better way than in the end
origin: ['埃尔多安', '的', '悲剧性', '选择']
reference: erdoğan ’s tragic choice
candidate: targeted in the run by erdoğan ’s tragic choice
对于这种短句子,一般翻译的效果都是比较不错的,起码语义上是对应的上的,其实这个翻译出来的句式是没有问题的,就是在最后的词性上运用不太对,感觉是因为训练样本中没有提供更加丰富的表达形式导致的,如果能有一条语句对应多条翻译的数据的话,表现应该会更好。
origin: ['在', '大部分', '发达', '国家', '中产', '阶级', '的', '收入', '增长', '早就', '停滞不前', '了', '而且', '就业', '机会', '也', '一直', '在', '减少', '尤其是', '经济', '中', '的', '可', '贸易', '部分']
reference: income growth for the middle class in most advanced countries has been stagnant and employment opportunities have been declining especially in the tradable part of the economy
candidate: and employment opportunities have been reduced in the tradable part of the eurozone – in addition to reducing trade in the tradable and of the world
对于这种较长的句子,一眼看过去就有很大的语言组织改进空间,虽然Bleu分数在整体不算低,但是语序其实感知起来比较混乱,怀疑可能是因为在数据处理的时候把标点符号都去掉了的原因,导致模型比较难学到断句的部分,这可能也是短句子翻译效果比较好的一个点,因为去掉标点符号没有影响语序。
在挑选样例的过程中,竟然还发现了一条自动纠错了的翻译结果:
origin: ['监控', '西藏', '和', '四川', '地震']
reference: big brother tibet and the sichuan earthquake
candidate: monitoring tibet and the sichuan earthquake
可以看到,参考翻译里面其实是不符合中文语义的,但是在我们模型翻译出来的candidate正确的把"监控"翻译成了"monitoring",这个现象说明这个模型还是真的学到了东西的。
{kind=link}
{kind=link}